
zure Synapse Analytics 是一项针对大型公司的无限信息分析服务,它被呈现为 Azure SQL 数据仓库 (SQL DW) 的演变,将业务数据存储和宏或大数据分析结合在一起。
在处理、管理和提供数据以满足即时商业智能和数据预测需求时,Synapse 为所有工作负载提供单一服务。后者通过与 Power BI 和 Azure 机器学习的集成而成为可能,因为 Synapse 能够使用 onNX 格式集成数学机器学习模型。它提供了处理和查询大量信息的自由度.作为微软在西班牙为数不多的 Power BI 合作伙伴之一,在 Bismart,我们在使用 Power BI 和 Azure Synapse 方面拥有丰富的经验。
Azure Synapse 分析如何工作?
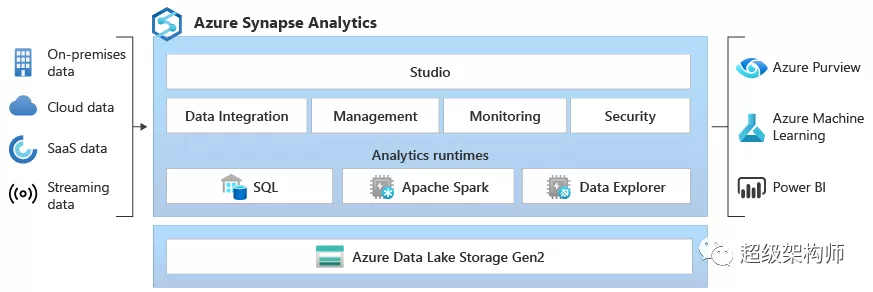
微软的服务是SaaS(软件即服务),可以按需使用,只在需要的时候运行(这对成本节约有影响)。它有四个组成部分:
具有完整基于 T-SQL 的分析的 SQL 分析:SQL 集群(按计算单位付费)和 SQL 按需(按处理的 TB 付费)。Apache Spark 完全集成。具有多个数据源的连接器。
Azure Synapse 使用 Azure Data Lake Storage Gen2 作为数据仓库和包含管理、监视和元数据管理部分的一致数据模型。在安全领域,它允许您保护、监视和管理您的数据和分析解决方案,例如使用单点登录和 Azure Active Directory 集成。基本上,Azure Synapse 完成了整个数据集成和 ETL 过程,它不仅仅是一个普通的数据仓库,因为它包括该过程的进一步阶段,使用户还可以创建报告和可视化。
在编程语言支持方面,它提供了 SQL、Python、.NET、Java、Scala 和 R 等多种语言的选择。这使其非常适合不同的分析工作负载和不同的工程配置文件。
一切都包含在 Synapse Analytics Studio 中,可以轻松地将人工智能、机器学习、物联网、智能应用程序或商业智能集成到同一个统一平台中。
使用 T-SQL 和 Spark
关于执行时间,它允许两个引擎。一方面是传统的 SQL 引擎 (T-SQL),另一方面是 Spark 引擎。通过这种方式,可以将 T-SQL 用于批处理、流式处理和交互式处理,或者在需要使用 Python、Scala、R 或 .NET 进行大数据处理时使用 Spark。
在这里,它直接链接到 Azure Databricks,这是一种基于 Apache Spark 的人工智能和宏数据分析服务,允许在交互式工作区中对共享项目进行自动可扩展性和协作。Azure Synapse 在两种服务之间提供了一个高性能连接器,可实现快速数据传输。这意味着可以继续使用 Azure Databricks(Apache Spark 的优化)和专门用于提取、转换和加载 (ETL) 工作负载的数据架构,以大规模准备和塑造数据。反过来,Azure Synapse 和 Azure Databricks 可以对 Azure Data Lake Storage 中的相同数据运行分析。
Azure Synapse 和 Azure Databricks 为我们提供了更大的机会,可以将分析、商业智能和数据科学解决方案与服务之间的共享数据湖相结合。
在实现最大兼容性和功率的道路上
最初,Microsoft 服务是作为公司必须面对的两个基本问题的解决方案而提出的。首先是兼容性。它集成的数据分析系统能够同时处理传统系统和非结构化数据以及各种数据源。因此,它能够分析存储在系统中的数据,例如客户数据库(姓名和地址位于像电子表格一样排列的行和列中)以及存储在数据湖中的镶木地板格式的数据。
但它还在自动处理任务以构建用于分析数据的系统方面提供了更大的多功能性。这种增强的功能直接导致减少了程序员所需的工作量,并延长了项目开发时间(它是第一个也是唯一一个以 PB 级执行所有 TPC-H 查询的分析系统)。
Azure Synapse 实现了需要几个月的项目可以在几天内完成,或者需要几分钟或几小时的复杂数据库查询现在只需几秒钟。
毫秒内成功协商
除了单独扩展进程和存储资源之外,Azure Synapse Analytics 还因其结果缓存功能而脱颖而出(它具有完全托管的 1 TB 缓存)。因此,当进行查询时,它会存储在此缓存中,以加快使用相同类型数据的下一个查询。
这是它能够在毫秒内引发响应的关键之一。这是因为缓存在暂停、恢复和扩展操作(可以通过为云设计的大规模并行处理架构非常快速地激活)中幸存下来。
工作负载和性能
同样值得注意的是它对 JSON 的全面支持、数据屏蔽以确保高水平的安全性、对 SSDT(SQL Server 数据工具)的支持,尤其是工作负载管理以及如何对其进行优化和隔离。在这里,多个工作负载共享实现的资源。这使得创建工作负载并为其分配 CPU 数量和并发性成为可能。
例如,在拥有 1000 个 DWU(数据仓库单元)的情况下,Azure Synapse 有助于将工作的一部分分配给销售,另一部分分配给市场营销(例如 60% 分配给一个,40% 分配给另一个)。这个想法是为了便于管理和优先考虑数据库查询。
在数据准备和摄取方面,它支持以集成方式流式传输(Native SQL Streaming)以生成分析,例如与事件中心或物联网中心集成。它通过实现高达 200MB/秒的高性能、以秒为单位的交付延迟、随计算规模扩展的摄取性能以及使用基于 Microsoft SQL 的组合、聚合、过滤器查询的分析能力来实现这一目标……
一些附加功能
最后,我们必须强调 Azure Synapse Analytics 的其他有趣方面,这些方面有助于加快数据加载和促进流程。其中有:
对于数据准备和加载,复制命令不再需要外部表,因为它允许您将表直接加载到数据库中。它提供对标准 CSV 的全面支持:换行符和自定义分隔符以及 SQL 日期。提供用户控制的文件选择(通配符支持)机器学习支持:可以以 onNX 格式创建和保存机器学习模型,这些模型存储在 Azure Synapse 数据存储中并与本机 PREDICT 指令一起使用。
与 Data Lake 集成:来自 Azure Synapse,文件以 Parquet 格式在 Data Lake 中读取,从而实现了更高的性能,将 Polybase 执行提高了 13 倍以上。
简而言之,一种保证开发线的服务,以确保 SQL DW 客户可以继续在生产中运行现有的数据存储工作负载并自动受益于新功能。



